
Compound failure
Why AI Agent Workflows Keep Failing

“Large language models are like that colleague of yours, who is very smart, has read a lot of books, and is always happy to help. Except they occasionally take recreational drugs, and you never know when.”
If you saw me speak recently, you’ve heard that line. It’s a powerful, even if not entirely scientific, metaphor that helps people have the right mindset towards GenAI. Treat GenAI as powerful and assume it can be confidently wrong.
Take hallucinations. Even top-tier models will fabricate facts. Many reports put hallucinations at double-digit levels. The industry is struggling to reduce botshit, but experts mostly agree that with current approaches, we might never achieve hallucination-free GenAI. (In a post last year, I argued that hallucinations aren’t always unwelcome: creativity has its place. Here, though, let’s assume hallucinations are an unwanted behaviour.)
In a copilot setup, or simply a GenAI chat, this is manageable. The process is as follows: human prompts, model responds, human inspects, errors get spotted, the response is improved through a follow-up prompt, and course corrections are applied. This AI creation, when paired with human curation, yields outstanding outcomes. Together, the pair routinely beats either actor alone in quality.
In 2025, however, the conversation has shifted to AI agents and AI agent workflows. These AI agents run on the same core technology: large language models. But they operate differently from copilots. Instead of a back-and-forth with a human, they run tools, hand work to other agents, and execute multi-step workflows (see, for instance, AI agent orchestration patterns for examples of such complex workflows).
Now remember our “occasionally high” colleague? Multiply by ten and remove the supervisor. What could go wrong?
Everything.
An agent that might be high, calling an agent that might be high, calling an agent that might be high.
It’s literally a telephone game. Even worse. It’s a telephone game where each player can speak with absolute confidence and clarity, even when it’s wrong. And there’s no adult in the room.
Compound Interest. But in Reverse
There’s a saying, wrongly attributed to almost everyone, including Einstein, Rockefeller and Warren Buffett, that “compound interest is the eighth wonder of the world.” Regardless of who coined it, it is a magical force that turns small investments into fortunes through exponential growth.
Copilots are what compound interest looks like in AI. A proper back-and-forth with a human makes quality go up with each pass. You prompt, the model drafts, you correct, add constraints, and steer. The next draft is better because the system now includes your judgment, domain rules, and context. Errors shrink, instructions sharpen, and output improves. Do three passes, and quality doesn’t just add, it multiplies. Compound improvement.

In AI agent chains, it has its evil twin: compound failure. The same mathematics, but working against you. An agent that’s 90% correct, calling an agent that’s 90% correct? That’s roughly 81% correctness now. Add a third 90%-correct agent to the chain, and we’re down to ~73%. Line up 15 agents like that… and the result will be correct only ~21% of the time.
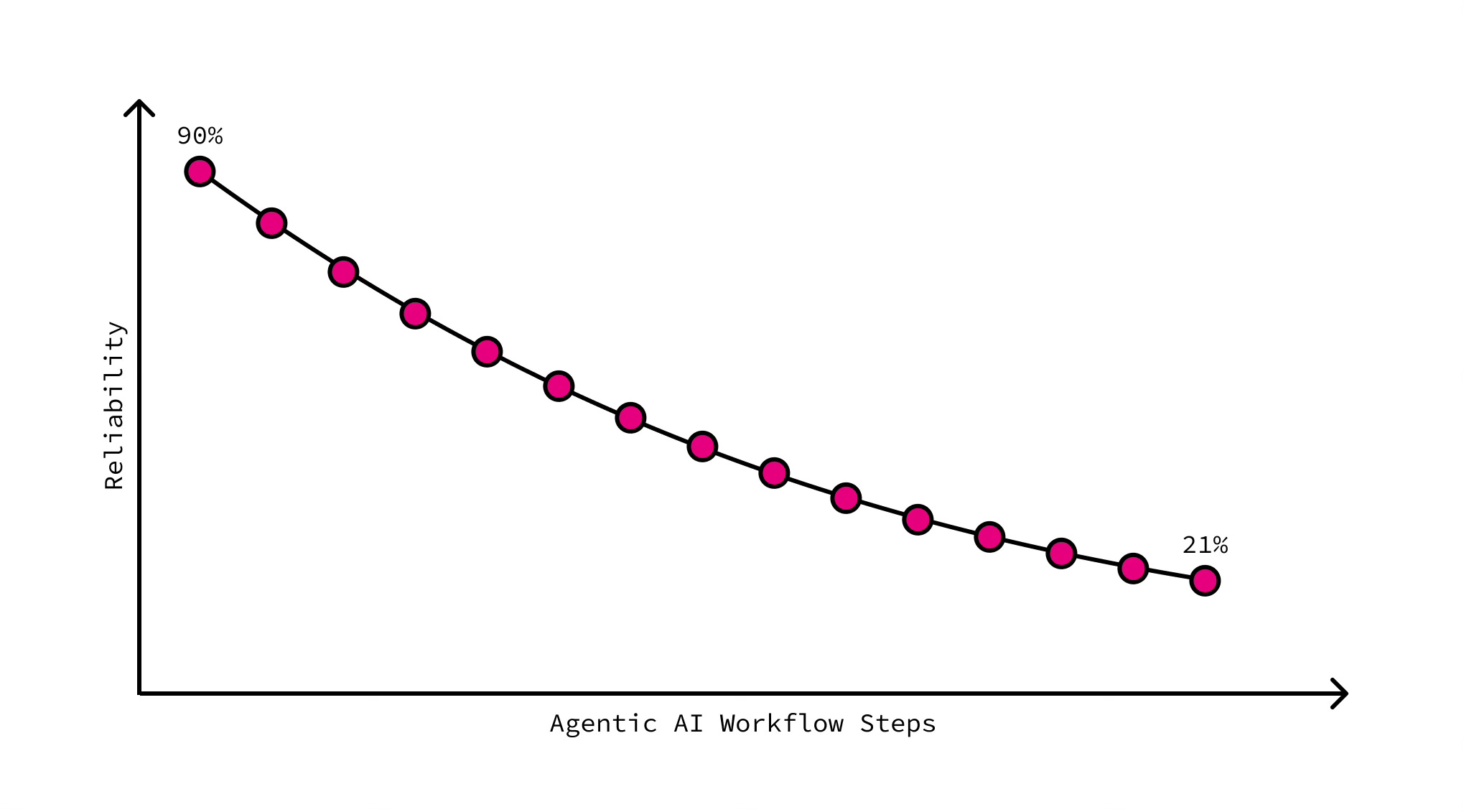
The reliability of a sequential AI workflow is a product (as in: multiplication) of the individual agent reliabilities at each step.
Each agent doesn’t just add risk. It multiplies it.
Now, you, a sharp reader, might object: “But some agents could catch and correct errors from previous ones!” True. But that assumes your error-checking agent is somehow more reliable than your error-making agent. It's turtles all the way down, except the turtles are high. And on roller skates.
The optimistic bit: we can flip the math. Either (1) raise per-agent reliability, via architectures that constrain variance, independent verification layers, and checks by heterogeneous models, or (2) reset the chain with human verification steps that stop errors from compounding. If you’re a small business, you probably won’t build new architectures yet; that’s AI-research territory. But you can absolutely do the second today. Start by limiting autonomous hops to just a couple and adding a human sign-off before money moves, decisions are approved, or anything goes public. Do either of these two well, and suddenly, compound failure becomes manageable, not fatal.
10-90-35
Let’s look again at the bit of math that should keep CTOs awake. Imagine a tidy sequence of ten agents, each one “ninety per cent reliable.” On paper, that sounds fine. Until you multiply them. Ninety per cent, ten times, gives you roughly thirty-five per cent end-to-end reliability. In other words, for every three runs, two disappoint. Even shorter chains don’t save you as much as you’d hope. Six agents at a respectable ninety-five per cent each land you under seventy-five per cent overall. Would you sign off on a process where one in four outcomes is wrong?
That tidy multiplication is the rosy case because it assumes independence: each mistake is fresh and uncorrelated. Real systems don’t behave that politely. The same flawed assumption can echo from step one to step six. The same brittle tool can misfire in the same way. Your “checker”, trained the same way as your “maker”, can miss the same flaw. Correlation will drag the totals down further than the clean equation suggests.
Even tiny error rates balloon with depth. One per cent error rate per step sounds harmless, right? Wrong. Stack a hundred steps and only about thirty-seven per cent of runs will survive intact (0.99¹⁰⁰≈0.37). Your agents don't need recreational drugs to fail - mathematics alone guarantees it.
You can see the market signal already. Copilots (human in charge, one hop, visible output) are thriving. I don’t even need to mention ChatGPT’s or Claude’s growing usage. Everyone knows that. GitHub Copilot? Massive success. Microsoft Copilot? I might think it’s not very good, but it’s still growing fast. Complex autonomous agent systems? Cricket sounds. Or, more specifically: pitch decks, demos, YouTube videos, but no real-life use cases (please prove me wrong: in my research group, we keep looking for real-life examples).
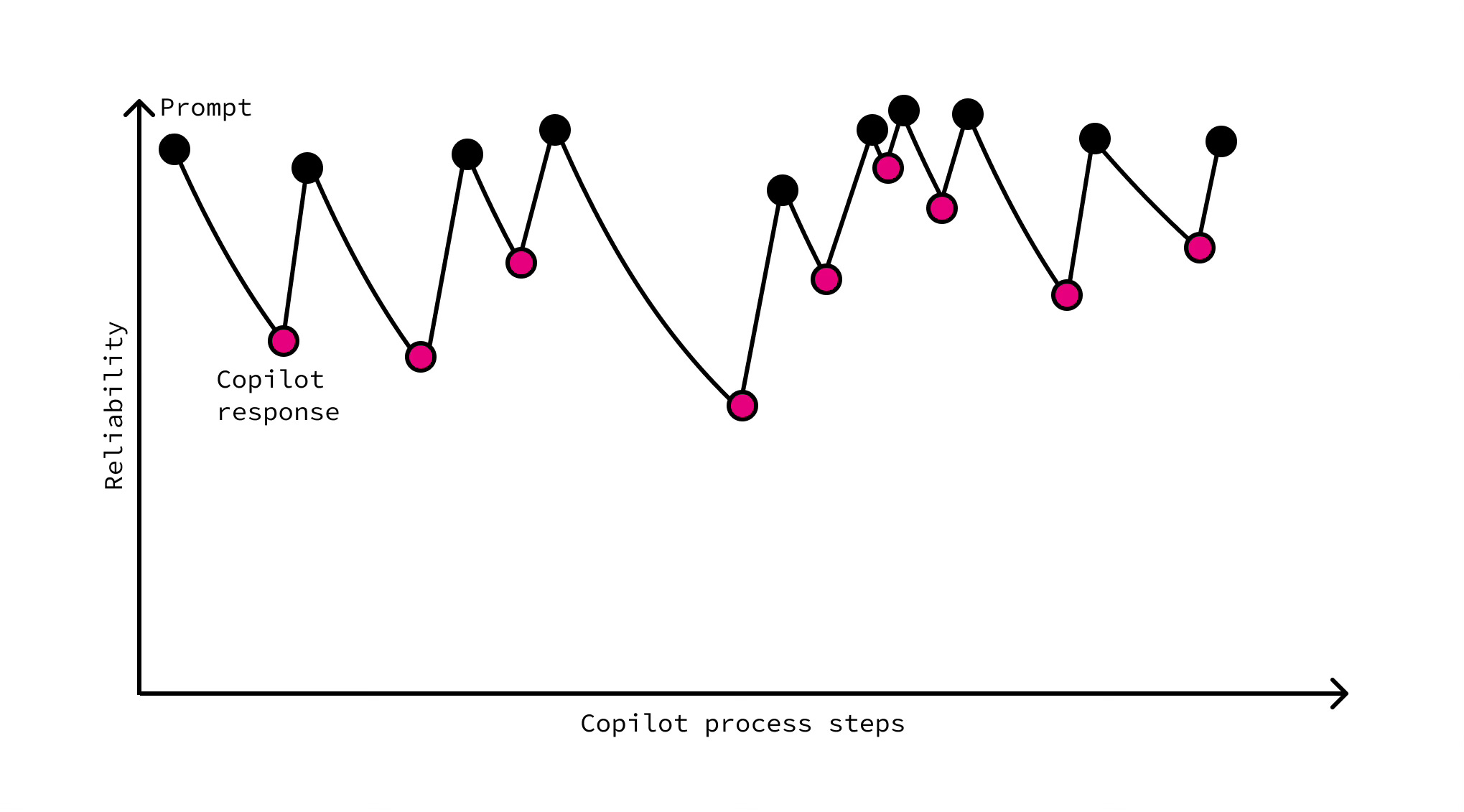
My point isn’t to scare you off; it’s to give you a design constraint. Treat 10-90-35 (or a similar set of numbers) as a warning. Ten steps at 90 per cent reliability means a 35 per cent success rate. What is your number? 2-95-90? 3-99-97? Push per-agent reliability, build smarter architectures and add reliable checks, or break the chain with human verification gates before errors can snowball.
How to tame the evil twin
There’s a short-term and a long-term approach here.
Right now, favour patterns that keep humans involved. Not just “in the loop” (whatever this means), but really, truly, in the workflow. Stick to copilots where you can. When you do use agents, make them “one-and-done”: one agent, one task, one human checking the output before anything irreversible happens. Just like you use, or should be using, ChatGPT. If you wouldn’t trust it to run a Taco Bell’s drive-through (18,000 water cups, anyone?), don’t trust it to run your business. And cap the workflow chains for now. “No more than three autonomous hops before a human gate”.
Next (and this is for the techies in your organisation), build toward architectures that raise per-agent reliability and reduce variance. Redundancy and voting can help, but only if the voters aren’t clones. If you ask GPT5 to check GPT5’s output, you’ve created a very confident echo chamber. Groupthink, anyone?
Add independent verification layers so the “checker” doesn’t inherit the “maker’s” errors. And yes, bring humans into the workflow deliberately. Not because it sounds responsible, but because supervision is the cheapest way to reset the chain before errors compound.
Vendors will try to sell you past the math. Let them try. Keep the $100-a-month tool that saves your assistant four hours a week. For the $50,000 “autonomous agent orchestration platform,” ask for their cascade-decay calculations. If they can’t show how a string of ninety-fives stays reliable, you’re not buying an agent platform. You’re buying a demo.
Until someone tames compound failure, either by engineering higher per-step reliability or by inserting human verification gates at the right moments, the most advanced AI strategy isn’t “more autonomy,” it’s less autonomy per workflow. Fewer hops. Clear quality gates. Strong verification. That’s how we get from clever demos to agentic workflows that actually work.
Really helpful as always Marek